
Deepmind语音生成模型WaveNet正式商用:效率提高1000倍
雷锋网消息:2017年10月4日,Deepmind发表博客称,其一年前提出的生成原始音频波形的深层神经网络模型WaveNet已正式商用于Google Assistant中,该模型比起一年前的原始模型效率提高1000倍,且能比目前的方案更好地模拟自然语音。
以下为Deepmind博客所宣布的详细信息,雷锋网摘编如下
一年之前,我们提出了一种用于生成原始音频波形的深层神经网络模型WaveNet,可以产生比目前技术更好和更逼真的语音。当时,这个模型是一个原型,如果用在消费级产品中的计算量就太大了。
在过去12个月中,我们一直在努力大幅度提高这一模型的速度和质量,而今天,我们自豪地宣布,WaveNet的更新版本已被集成到Google Assistant中,用于生成各平台上的所有英语和日语语音。
新的WaveNet模型可以为Google Assistant提供一系列更自然的声音。
为了理解WaveNet如何提升语音生成,我们需要先了解当前文本到语音(Text-to-Speech,
TTS)或语音合成系统的工作原理。
目前的主流做法是基于所谓的拼接TTS,它使用由单个配音演员的高质量录音大数据库,通常有数个小时的数据。这些录音被分割成小块,然后可以将其进行组合以形成完整的话语。然而,这一做法可能导致声音在连接时不自然,并且也难以修改,因为每当需要一整套的改变(例如新的情绪或语调)时需要用到全新的数据库。
另一方案是使用参数TTS,该方案不需要利用诸如语法、嘴型移动的规则和参数来指导计算机生成语音并进行语音拼接。这种方法即便宜又快捷,但这种方法生成的语音不是那么自然。
WaveNet采取完全不同的方法。在原始论文中,我们描述了一个深层的生成模型,可以以每秒处理16000个样本、每次处理一个样本党的方式构建单个波形,实现各个声音之间的无缝转换。

WaveNet使用卷积神经网络构建,在大量语音样本数据集上进行了训练。在训练阶段,网络确定了语音的底层结构,比如哪些音调相互依存,什么样的波形是真实的以及哪些波形是不自然的。训练好的网络每次合成一个样本,每个生成的样本都考虑前一个样本的属性,所产生的声音包含自然语调和如嘴唇形态等参数。它的“口音”取决于它接受训练时的声音口音,而且可以从混合数据集中创建任何独特声音。与TTS系统一样,WaveNet使用文本输入来告诉它应该产生哪些字以响应查询。
原始模型以建立高保真声音为目的,需要大量的计算。这意味着WaveNet在理论上可以做到完美模拟,但难以用于现实商用。在过去12个月里,我们团队一直在努力开发一种能够更快地生成声波的新模型。该模型适合大规模部署,并且是第一个在Google最新的TPU云基础设施上应用的产品。

(新的模型一秒钟能生成20秒的音频信号,比原始方法快1000倍)
WaveNet团队目前正在准备一份能详细介绍新模型背后研究的论文,但我们认为,结果自己会说话。改进版的WaveNet模型仍然生成原始波形,但速度比原始模型快1000倍,每创建一秒钟的语音只需要50毫秒。该模型不仅仅速度更快,而且保真度更高,每秒可以产生24,000个采样波形,同时我们还将每个样本的分辨率从8bit增加到16bit,与光盘中使用的分辨率相同。
这些改进使得新模型在人类听众的测试中显得发声更为自然。新的模型生成的第一组美式英语语音得到的平均意见得分(MOS)为4.347(满分5分),而真实人类语音的评分只有4.667。
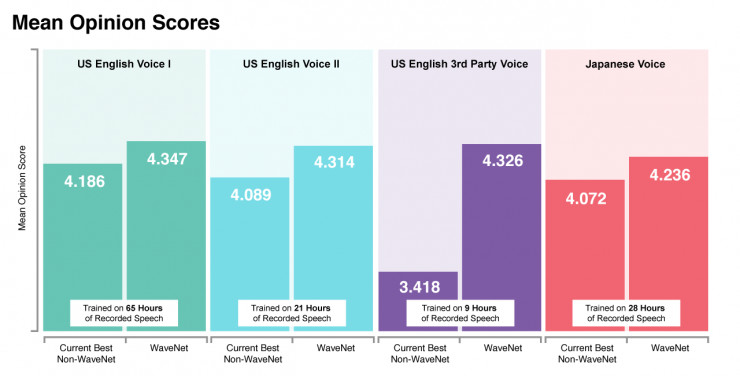
新模式还保留了原始WaveNet的灵活性,使我们能够在训练阶段更好地利用大量数据。具体来说,我们可以使用来自多个语音的数据来训练网络。这可以用于生成高质量和具有细节层次的声音,即使在所需输出语音中几乎没有训练数据可用。
我们相信对于WaveNet来说这只是个开始。我们为所有世界语言的语音界面所能展开的无限可能而兴奋不已。
(Via
Deepmind
,雷锋网编译)
